I’ve finally completely rid myself of Mendeley and so now I’ve been building up a workflow to replace its functionality. I’ve been using cb2bib for metadata extraction, which works quite well, saving the metadata to a BibTeX file. I’ve also been maintaining a basic, searchable database of literature with my notes in org-mode for Emacs (adapted from this setup).
The main thing that I was missing was a way of keeping track of which
papers I still have not read. So, I started with a basic shell script,
called paperq, to maintain a queue of papers: files are added to the
queue and then when you run the script it opens the next paper. Then
it slowly built up from there with new convenient features being
added. I’ve been finding it to be really useful so I’ve packaged it
up in case others might need something like it.
paperq is a command-line tool. It’s
usage is simple: you add files to the queue with the -a option (you
can remove with the -r flag). When you run it without arguments the
next file in the queue is opened. The queue part of the code itself is
rather simple but paperq also offers some other nice features:
- Display info on a file. Given a BibTeX file, print the bibliographic information, otherwise print the file location (-i option)
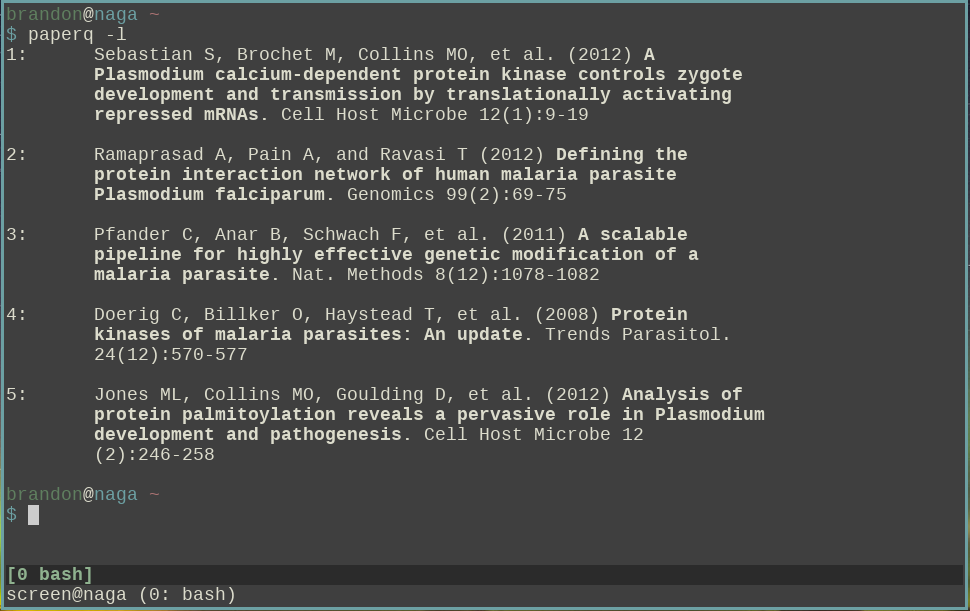
- List all files (or bibliographic information) in the queue (-l option)
- Create an archive (tar.gz) of the papers in the queue, prepending the file names with the queue position (-x option)
- Operate on any file in the queue, instead of the head, via the -n option
- Peek at a file (open it, but don’t remove it from the queue) via the -p option
- Print a file (-t option)
- Configurable file-opening command (xdg-open %s, by default)
Documentation is available in the README file or on the website. A man page is also included.
I’ve been using it myself now that I finally stopped using Mendeley. I find it to be quite handy, so I’ve packaged it up to be shared with others.
Screenshot showing the bibliographic info:
You can download version 1.0 from the website. For users of Arch Linux and related distros, it’s available in the AUR.